
Stable Diffusion là một mô hình AI mạnh mẽ có khả năng tạo ra hình ảnh từ các mô tả văn bản. Bạn chỉ cần cung cấp một câu lệnh như “một chú mèo đội mũ cao trong tàu vũ trụ” và mô hình sẽ tạo ra hình ảnh đúng như vậy! Sự chính xác của hình ảnh thường phụ thuộc vào độ cụ thể của câu lệnh bạn nhập vào.
Tuy nhiên, nếu bạn muốn tạo ra những hình ảnh theo phong cách cụ thể hoặc với những yếu tố độc đáo, việc đào tạo mô hình Stable Diffusion riêng sẽ là lựa chọn lý tưởng. Bài viết này sẽ hướng dẫn bạn qua từng bước của quá trình.
Hiểu Về Cách Hoạt Động Của Stable Diffusion
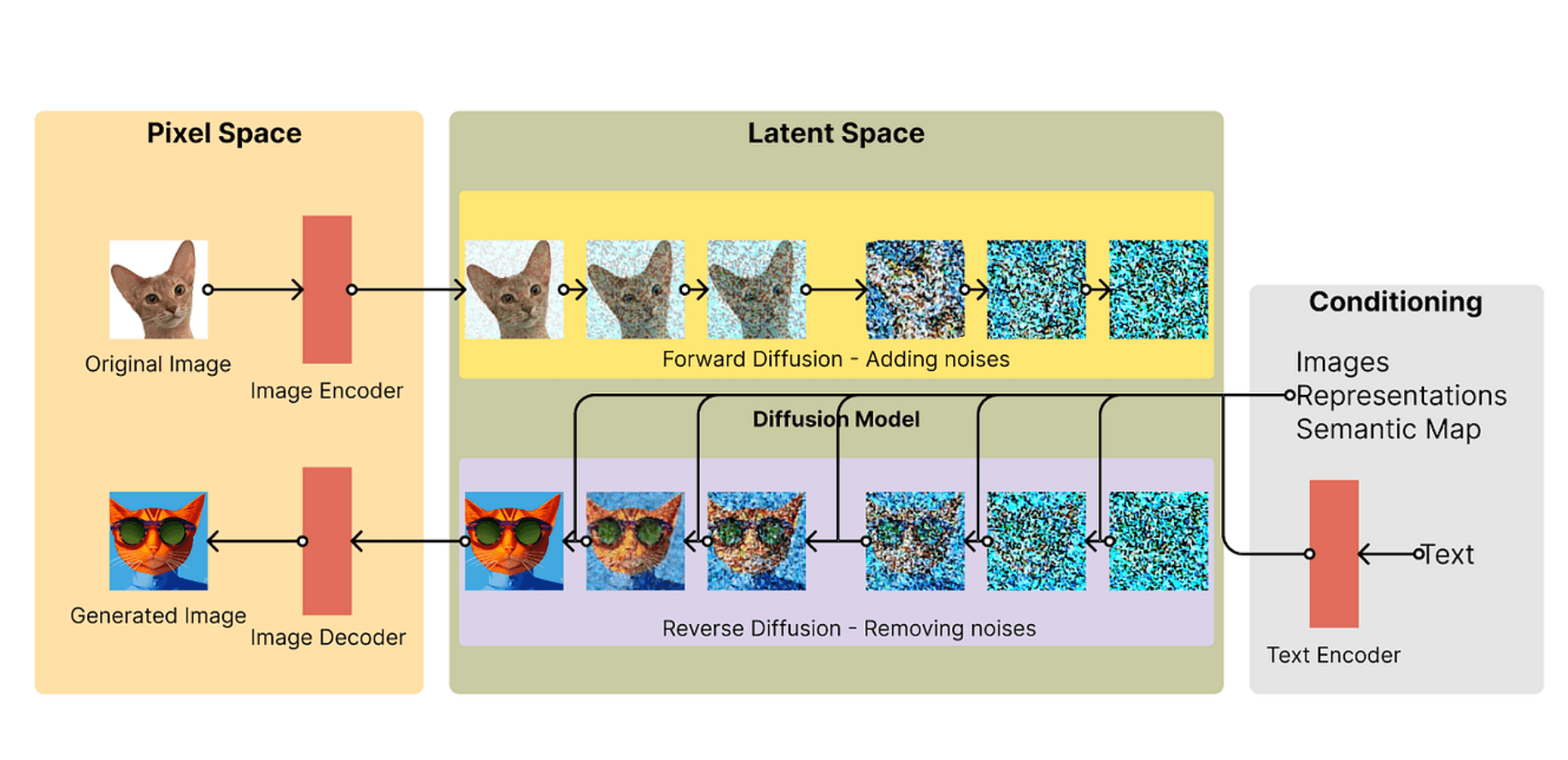
Trước khi đi vào chi tiết cách thức đào tạo, hãy cùng tìm hiểu cách mà Stable Diffusion học hỏi. Có hai khái niệm chính: “Pixel Space” và “Latent Space”.
Datasets
Stable Diffusion được đào tạo trên các tập dữ liệu lớn bao gồm hình ảnh và mô tả văn bản tương ứng. Những dữ liệu này giúp mô hình hiểu mối quan hệ giữa từ ngữ và các yếu tố hình ảnh.
Quá Trình Khuếch Tán
Mô hình học bằng cách từ từ thêm nhiễu vào hình ảnh và sau đó cố gắng đảo ngược quy trình đó. Điều này giúp mô hình hiểu cấu trúc cơ bản của hình ảnh.
Bộ Encoder Văn Bản
Khi bạn đưa một câu lệnh cho mô hình, nó sử dụng bộ mã hóa để chuyển đổi từ ngữ thành một biểu diễn toán học. Chỉ sau đó, nó mới bắt đầu tạo ra hình ảnh thực tế.
Bộ Giải Mã Hình Ảnh
Cuối cùng, mô hình sử dụng bộ giải mã hình ảnh để chuyển đổi biểu diễn toán học thành hình ảnh.
Các Bước Để Đào Tạo Mô Hình Stable Diffusion
Dưới đây là những bước cụ thể để bạn có thể bắt đầu đào tạo mô hình của riêng mình.
1. Thu Thập Dữ Liệu Đào Tạo
Đầu tiên, bạn cần thu thập hình ảnh và mô tả chúng. Đây là bước quan trọng nhất trong việc dạy cho mô hình những gì cần học. Khi chọn hình ảnh, hãy đảm bảo rằng bộ dữ liệu của bạn đa dạng. Điều này giống như việc trẻ em nhận biết chó qua nhiều giống khác nhau về kích thước và màu sắc. Hình ảnh đa dạng sẽ giúp mô hình tổng quát tốt hơn và chính xác hơn.
Mô tả cũng rất quan trọng. Chúng nên ngắn gọn và rõ ràng, cung cấp thông tin liên quan về hình ảnh. Ví dụ, một mô tả về bức ảnh của Tháp Eiffel có thể bao gồm vị trí, thời gian trong ngày, và mùa mà hình ảnh được chụp.
Một số điểm kỹ thuật quan trọng cần lưu ý:
- Chất lượng hình ảnh: Sử dụng hình ảnh chất lượng cao, rõ nét và đủ ánh sáng.
- Độ đa dạng hình ảnh: Bao gồm một loạt các hình ảnh đại diện cho phong cách hoặc các yếu tố mà bạn muốn mô hình tạo ra.
- Chú thích mô tả: Viết chú thích rõ ràng và chi tiết cho mỗi hình ảnh, sử dụng từ khóa miêu tả nội dung, phong cách và tâm trạng.
- Kích thước tập dữ liệu: Một tập dữ liệu lớn hơn thường dẫn đến kết quả tốt hơn. Bạn nên nhắm tới ít nhất vài trăm hình ảnh để bắt đầu.
2. Thiết Lập Môi Trường Đào Tạo
Đào tạo các mô hình AI yêu cầu phần mềm và phần cứng đặc biệt. Bạn có hai lựa chọn chính:
- Điện toán đám mây: Các dịch vụ như Google Colab và Amazon SageMaker cung cấp môi trường dựa trên đám mây, với sức mạnh tính toán cần thiết, giúp bạn dễ dàng bắt đầu.
- Máy tính cục bộ: Nếu bạn sở hữu máy tính mạnh, bạn có thể thiết lập môi trường cục bộ bằng các framework như PyTorch hoặc TensorFlow. Tùy chọn này giúp bạn kiểm soát tốt hơn nhưng yêu cầu kiến thức kỹ thuật nhiều hơn.
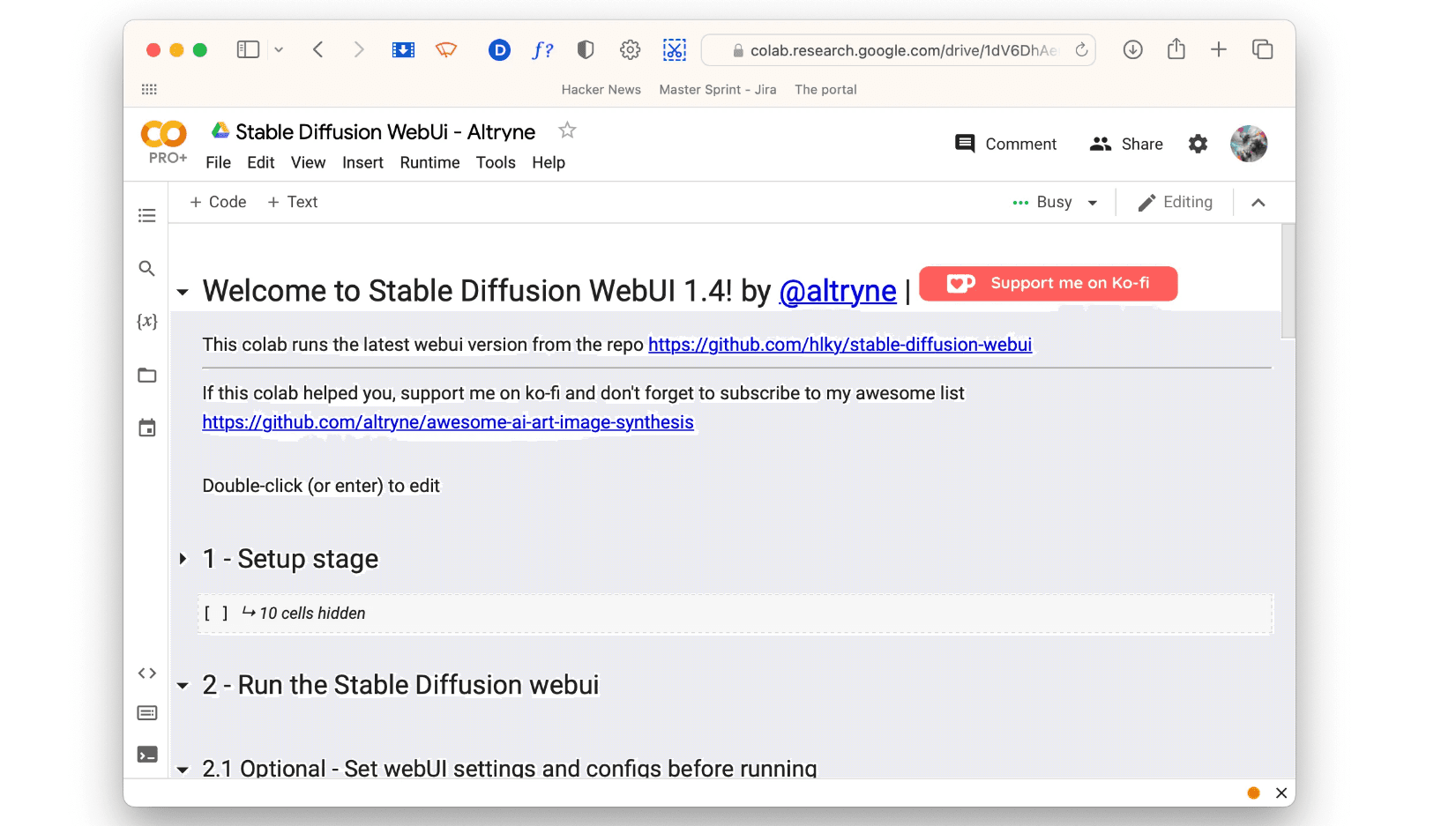
Google Colab là cách đơn giản nhất để chạy Stable Diffusion. Tại sao? Vì nó hoạt động như Google Docs cho mã code và chạy trên máy chủ của Google. Bạn có thể sử dụng Colab miễn phí, tuy nhiên, nếu bạn thường xuyên sử dụng Stable Diffusion, tôi khuyên bạn nên nâng cấp lên Pro hoặc Pro+ để có GPU mạnh mẽ hơn và thời gian phiên dài hơn.
3. Chọn Mô Hình Được Đào Tạo Trước Hoặc LoRa
Khi đào tạo mô hình Stable Diffusion, bạn không nhất thiết phải bắt đầu từ đầu. Thay vào đó, bạn có thể tận dụng các mô hình đã được đào tạo trước và tinh chỉnh chúng với tập dữ liệu của riêng bạn. Cách tiếp cận này giúp bạn tiết kiệm thời gian và tài nguyên đáng kể.
Các mô hình đã được đào tạo trước này khá đa dạng. Stable Diffusion v1.5 là một mô hình linh hoạt, có khả năng xử lý nhiều nhiệm vụ tạo hình ảnh khác nhau. Waifu Diffusion lại chuyên về việc tạo ra nhân vật anime. Ngoài ra, còn có Dreamlike Diffusion, tạo ra hình ảnh mộng mị và siêu thực. Bạn có thể tìm thấy các mô hình này trên các nền tảng như Hugging Face.
4. Tiền Xử Lý và Tăng Cường Dữ Liệu
Trước khi tiến hành đào tạo, bạn cần chuẩn bị tập dữ liệu của mình:
- Thay đổi kích thước: Đảm bảo tất cả hình ảnh có kích thước giống nhau, thường là định dạng vuông như 512×512 pixel.
- Chuẩn hóa: Điều chỉnh dữ liệu hình ảnh về một tỷ lệ tiêu chuẩn, giúp mô hình học hiệu quả hơn.
- Tăng cường: Bạn có thể tăng kích thước và sự đa dạng của tập dữ liệu bằng cách áp dụng các biến đổi ngẫu nhiên như xoay, lật và điều chỉnh màu sắc.
Ground Truth đề cập đến dữ liệu thực tế được sử dụng để đào tạo, phục vụ như một chỉ tiêu đánh giá hiệu suất của mô hình. Mô hình sẽ cố gắng học từ dữ liệu gốc này để tránh lạc hướng trong quá trình đào tạo.
Boomerang là một phương pháp nhằm cải thiện mẫu tại chỗ trên các manifold hình ảnh sử dụng các mô hình khuếch tán. Nó liên quan đến việc đảo ngược một phần quy trình khuếch tán để tạo ra các mẫu gần với hình ảnh đầu vào đã cho.
5. Đào Tạo Mô Hình
Giờ đây, bạn đã sẵn sàng bắt đầu quá trình đào tạo!
- Hyperparameters: Đây là các thiết lập kiểm soát cách mô hình học, chẳng hạn như tốc độ học và kích thước lô. Thử nghiệm với các hyperparameter khác nhau có thể ảnh hưởng đến kết quả cuối cùng.
- Vòng lặp đào tạo: Quá trình đào tạo liên quan đến việc cung cấp tập dữ liệu cho mô hình nhiều lần, từ từ điều chỉnh các tham số của nó để giảm thiểu sai sót.
- Theo dõi tiến độ: Theo dõi tiến trình đào tạo bằng cách giám sát các chỉ số như mất mát (loss) và tạo ra các hình ảnh mẫu để xem cách mô hình đang học.
6. Đánh Giá Và Tinh Chỉnh Mô Hình
Sau khi quá trình đào tạo hoàn tất, bạn cần đánh giá hiệu suất của mô hình:
- Tạo hình ảnh mẫu: Kiểm tra mô hình bằng cách cung cấp các câu lệnh tương tự như trong tập dữ liệu đào tạo của bạn.
- Điều chỉnh Hyperparameters: Nếu bạn không hài lòng với kết quả, bạn có thể tinh chỉnh mô hình bằng cách điều chỉnh các hyperparameters hoặc đào tạo thêm trong nhiều epoch.
- Quá trình lặp lại: Đào tạo các mô hình AI thường mang tính lặp đi lặp lại. Bạn có thể cần quay lại và điều chỉnh tập dữ liệu, hyperparameters hoặc quy trình đào tạo để đạt được kết quả mong muốn.
Công Cụ và Tài Nguyên Để Đào Tạo Stable Diffusion
- Hugging Face Diffusers: Thư viện giúp đơn giản hoá công việc với Stable Diffusion và các mô hình khuếch tán khác, cung cấp công cụ cho việc đào tạo, tinh chỉnh và suy luận.
- Google Colab: Nền tảng đám mây miễn phí cung cấp quyền truy cập vào GPU, giúp dễ dàng hơn trong việc đào tạo các mô hình AI.
- Amazon SageMaker: Nền tảng máy học đám mây cung cấp công cụ và tài nguyên cho việc đào tạo và triển khai các mô hình AI.
- Civit.ai: Nơi có hàng trăm mô hình tồn tại trước, LoRAs, tập dữ liệu và thông tin hữu ích.
Khám Phá Tiềm Năng Của AI Với ChatLabs
Nếu bạn sẵn sàng khám phá thế giới tạo hình ảnh AI ngoài Stable Diffusion, ChatLabs cung cấp nền tảng toàn diện để thử nghiệm với nhiều mô hình AI tiên tiến.
ChatLabs bao gồm:
- DALL-E: Một mô hình tạo hình ảnh nổi tiếng với khả năng tạo ra các hình ảnh thực tế và tưởng tượng.
- Tích hợp Stable Diffusion: GPT-4 và GPT-4 Mini là các phiên bản mới nhất của các mô hình ngôn ngữ GPT, có thể tạo ra văn bản chất lượng con người.
- Claude, Mistral, và LLaMa: Nhiều mô hình ngôn ngữ khác nhau, mỗi mô hình đều có ưu điểm và khả năng riêng.
ChatLabs cho phép bạn khai thác sức mạnh của AI trong một ứng dụng web tiện lợi. Bắt đầu sáng tạo với công nghệ AI tiên tiến nhất ngay hôm nay!

Việc đào tạo mô hình Stable Diffusion không chỉ mở ra khả năng tạo ra hình ảnh theo ý tưởng cá nhân mà còn giúp bạn hiểu rõ hơn về cách thức hoạt động của công nghệ AI hiện đại. Hy vọng rằng hướng dẫn này đã giúp bạn hình dung được quy trình và các bước cần thiết để tạo ra một mô hình hiệu quả.